Getting started with Inseq
The Inseq library is a Pytorch-based toolkit inteded to democratize the access to some common use-cases in the study of sequence generation models for interpretability purposes. At the moment, the library supports the following set of models and techniques:
Models
All the models made available through the AutoModelForSeq2SeqLM interface of the 🤗 transformers library (among others, T5, Bart and all >1000 MarianNMT variants) can be used in combination with feature attribution methods.
All the models made available through the AutoModelForCausalLM interface of the 🤗 transformers library (among others, GPT-2, GPT-NeoX, Bloom and OPT/Galactica).
Interpretability Methods
At the moment, only gradient-based feature attribution methods sourced from the Captum library and basic attention attribution methods are available, but other popular occlusion and attention-based techniques will soon follow. The list of all available methods can be obtained by using the
list_feature_attribution_methods()method. Each method either points to its original implementation, and is thoroughly documented in its docstring.
Installing Inseq
The latest version of Inseq can be installed from PyPI using pip install inseq. To gain access to some Inseq functionalities, you will need to install optional dependencies (e.g. use pip install inseq[datasets] to enable datasets attribution via the Inseq CLI). For installing the dev version and contributing, please follow the instructions in Inseq readme file.
The AttributionModel class
The AttributionModel class is a torch.nn.Module intended to seamlessly wrap any sequence generation Pytorch model to enable its interpretability. More specifically, the class adds the following capabilities to the wrapped model:
A
load()method to load the weights of the wrapped model from a saved checkpoint, locally or remotely. This is called when using theload_model()function, which is the suggested way to load a model.An
attribute()method used to perform feature attribution using the loaded model.Multiple utility methods like
encode()andembed()that are also used internally by theattributemethod.
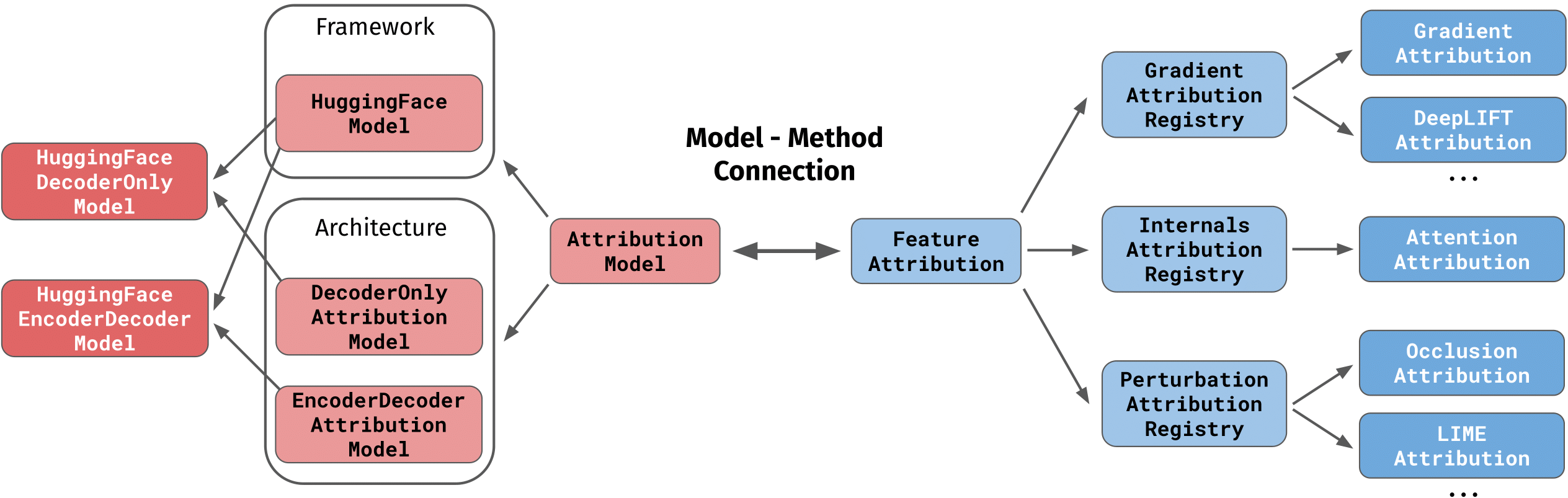
AttributionModel children classes belong to two categories: architectural classes like EncoderDecoderAttributionModel defines methods that are specific to a certain model architecture, while framework classes like HuggingfaceModel specify methods that are specific to a certain modeling framework (e.g. encoding with a tokenizer in 🤗 transformers). The final class that will be instantiated by the user is a combination of the two, e.g. HuggingfaceEncoderDecoderModel for a sequence-to-sequence model from the 🤗 transformers library.
When a model is loaded with load_model(), a FeatureAttribution can be attached to it to specify which feature attribution technique should be used on it. Different families of attribution methods such as GradientAttributionRegistry are made available, each containing multiple methods (e.g. IntegratedGradientsAttribution, DeepLiftAttribution).
The following image provides a visual hierarchy of the division between AttributionModel and FeatureAttribution subclasses:
The attribute method
The attribute() method provides a easy to use and flexible interface to generate feature attributions with sequence generation models. In its most simple form, the selected model is used to generate one or more output sequences with default parameters, and then those are attributed with the specified feature attribution method.
import inseq
model = inseq.load_model("Helsinki-NLP/opus-mt-en-fr", "saliency")
out = model.attribute(input_texts="Hello world, here's the Inseq library!")
The attribute method supports a wide range of customizations. Among others:
Specifying one string in
generated_textsfor every sentence ininput_textsallows attributing custom generation outputs. Useful to answer the question “How would the following output be justified in light of the inputs by the model?”.attr_pos_startandattr_pos_endcan be used to attribute only specific spans of the generated output, making the attribution process more efficient when one is only interested in attributions at a specific output step.output_step_attributionswill fill thestep_attributionsproperty in the output object with step-by-step attributions that are normally produced but then discarded after converting them in sequence attributions specific to every sequence in the attributed batch.attribute_targetcan be used to specify that target-side prefix should also be attributed for encoder-decoder models besides the original source-to-target attribution. This would populate thetarget_attributionfiled in the output, which would otherwise be left empty. In the decoder-only case, the parameter is not used since only the prefix is attributed by default.step_scoresallows for computing custom scores at every generation step, with some such as tokenprobabilityand output distributionentropybeing defined by default in Inseq.attributed_fnallows defining a custom output function for the model, enabling advanced use cases such as contrastive explanations.
The FeatureAttributionOutput class
In the code above, the out object is a FeatureAttributionOutput instance, containing a list of sequence_attributions and additional useful ìnfo regarding the attribution that was performed. In this example sequence_attributions has length 1 since a single sequence was attributed. Printing the output of the above result:
FeatureAttributionOutput({
sequence_attributions: list with 1 elements of type GradientFeatureAttributionSequenceOutput: [
GradientFeatureAttributionSequenceOutput({
source: list with 13 elements of type TokenWithId:[
'▁Hello', '▁world', ',', '▁here', '\'', 's', '▁the', '▁In', 'se', 'q', '▁library', '!', '</s>'
],
target: list with 12 elements of type TokenWithId:[
'▁Bonjour', '▁le', '▁monde', ',', '▁voici', '▁la', '▁bibliothèque', '▁Ins', 'e', 'q', '!', '</s>'
],
source_attributions: torch.float32 tensor of shape [13, 12, 512] on cpu,
target_attributions: None,
step_scores: {},
sequence_scores: None,
attr_pos_start: 0,
attr_pos_end: 12,
})
],
step_attributions: None,
info: {
...
}
})
The tensor in the source_attribution field contains one attribution score per model’s hidden size (512 here) for every source token (13 in this example, shown in source) at every step of generation (12, shown in target). The GradientFeatureAttributionSequenceOutput is a special class derived by the regular FeatureAttributionSequenceOutput that would automatically handle the last dimension of attribution tensors by summing an L2-normalizing via an Aggregator. This allows using the out.show function and automatically obtaining a 2-dimensional attribution map despite the original attribution tensor is 3-dimensional.